Summary
In application, argument flows to parameter & abstraction body value flows to application
See also
While nominally notes for the relevant PoPA chapter, this also incorporates explanations from these lecture notes from Jonathan Aldrich, these Harvard lecture slides, and this page from Matt Might.
Who cares?
With imperative programs, we can compile down to a control-flow graph and perform dataflow analysis on these graphs. However, when examining functional programs, this isn’t so obvious:
- There’s no clear notion of a “program point” with obvious predecessors or successors
- Computation is intrinsically nested
- Since functions are first-class, dispatch can be dynamic—the body of a function can transfer control to an arbitrary function passed in as an argument.
Control flow analysis is a form of program analysis, like dataflow analysis, that is more well-suited to performing analyses like constant propagation on functional languages. One property of control flow analysis is that along with recording the information we care about, we also record the possible functions every subexpression could evaluate into. This info is needed for performing analyses in the presence of first-class functions, since whenever we have a function application, we need to know what functions might be applied at that point (i.e., where control flow might be coming from or to).
This analysis is also called constraint-based analysis since it relies on the generation of constraints on analysis values for variables and expressions.
0-CFA analyses
Note
This exposition follows with both the Aldrich lecture notes and the textbook presentation. We’ll be switching back and forth where needed.
In this section, we’re going to build up to a constant propagation analysis on a functional language. We’ll get there eventually, but we’ll work up to it!
Now of course, we want to record analysis values for variables, but since functional languages rely on expressions, we also want to record analysis values for expressions as well. We do this by associating each expression with a label
Textbook difference
The textbook separates
into two components: an abstract environment , which has type and abstracts over execution environments, and , which has type an abstracts over execution profiles—traces of executed expressions. Additionally, instead of , they use . Additionally, you could get away with having an analysis just be from
if you transform to continuation-passing style or A-normal form, since all expressions become “labeled” by variables. We don’t do that here to show that this sort of analysis doesn’t require a transformation into e.g., CPS to work.
Before we get to a full constant propagation analysis, we’re gonna do a simpler analysis that this analysis depends on: figuring out what functions an expression can call! The values a function could return (and thus what constants an expression could evaluate to) depends on the functions it is transferring control flow to, and the arguments given to those functions.
In control flow analysis, at every occurrence of a function application, we want to be able to know what functions we might be calling at that point. In other words, whenever we see
So, how can we define this analysis? We define this analysis in terms of constraints over the possible analysis values for a variable or label. We then solve the constraints afterwards to get the most precise analysis value at each point.
In the Aldrich lecture notes, this analysis is given as inference rules that generate constraints. For instance, this rule states that a constant expression
Aldrich
Equivalently, the textbook defines an acceptability relation
Textbook
Now, let’s look at the how both treatments deal with the rule for variables. The rule broadly states that for a variable
Aldrich
Textbook
Note that at this point, they’re specializing for the set analysis, and aren’t thinking about lattices:
Since you’ve probably gotten a flavor for translating between Aldrich and the textbook, I’ll be using the textbook’s syntax from now on, since it’s more standard I guess.
When we encounter a function, it’s pretty straight-forward: we add a constraint that our analysis should include the fact that “this expression could evaluate to this lambda term”:
Textbook
Note that this definition doesn’t demand that we analyze the body of the function at all. Instead, we do this analysis at function application, since we don’t care about unreachable expressions.
Function application is more complex. Let’s say we have an application
- We must have valid analyses at
and . - For every function
in the analysis set for (i.e., the first expression): - We must have a valid analysis at the body of the function
, and - The possible set of functions that formal parameter
in the lambda could evaluate to must include the possible set of functions stood for by the argument , and - The set of function values this application can take on must include the values of the body of the function
.
- We must have a valid analysis at the body of the function
Textbook
Constraint flow rule-of-thumb
We can summarize the way that constraints flow thusly: the argument flows to the parameter, and the abstraction body flows to the application. Consider an application
- The argument flows to the parameter means that
flows to . That is, the analysis for must be a subset of the analysis for . . - Whatever analysis that holds for the argument must also hold for the parameter, since when the function is called, the parameter takes on at least that argument as its value.
- The parameter could take on other arguments in other places, hence why it’s argument subset parameter and not other way around.
- The body flows to the application means that
flows to . The analysis for must be a subset of the analysis for . - Function application will eventually yield
, the body of the abstraction. - The analysis for
will take into account all the possible concrete values of the parameter. - Thus, the analysis for
should also hold for , which provides one possible concrete value of the parameter. - This is an over-approximate analysis, since it assumes the analysis for
, which is taken assuming that could take on all sorts of values at different application points, is a subset of the analysis for . - But this is the safe, conservative estimate!
- Function application will eventually yield
In general, we can say that concrete values flow to abstract variables. Application arguments flow to formal parameters, and concrete return values or function bodies flow to the variables they’re assigned to.
Remember this rule of thumb. It will apply in general to the modifications of 0-CFA we will explore shortly.
Sensitivities and polyvariance
See also
This analysis has a number of properties:
- It is flow-insensitive: if we have an application
, even if our analysis of is empty (i.e., it can’t take on any lambda values), we still perform analysis of anyways. ^70155c - A flow-sensitive analysis would skip analyzing
if it determines to be empty. - This is because call-by-value (i.e., strict) semantics insists on a left-to-right calling order, which means that a flow-sensitive analysis—an analysis that takes into account order of execution and control flow—should analyze
first and use that to inform whether it should analyze . - By contrast, our flow-insensitive analysis ignores the semantics of our language, and analyzes both
and regardless. - See the notes for Exercise 3.3 on page 204 of the textbook.
- A flow-sensitive analysis would skip analyzing
- It is path-insensitive: when we encounter conditionals, the analysis for each branch doesn’t depend on or incorporate information about the predicate expression of the conditional.
- From Wikipedia: “A path-sensitive analysis computes different pieces of analysis information dependent on the predicates at conditional branch instructions. For instance, if a branch contains a condition
x>0, then on the fall-through path, the analysis would assume thatx<=0and on the target of the branch it would assume that indeedx>0holds.”
- From Wikipedia: “A path-sensitive analysis computes different pieces of analysis information dependent on the predicates at conditional branch instructions. For instance, if a branch contains a condition
- It is context-insensitive: the analysis treats all function calls to the same function the same, regardless of where that function is being called. We’ll go over this in depth in Context sensitivity k-CFAs and m-CFAs.
- Note that monovariance is another word for context insensitivity, and polyvariance is another term for context sensitivity.
On flow- and context-sensitivity and -insensitivity
Alias Analysis for Object-Oriented Programs provides a more detailed look at flow-sensitivity & -insensitivity and context-sensitivity & -insensitivity.
Adding dataflow information
Note
This references §3.5 of the textbook.
Now, let’s return to our constant propagation problem. We don’t want to just keep track of what expressions call what functions; we want to keep track of other information as well, like we might with a dataflow analysis!
Basically, we can just extend the abstract domain true or false bool, or if they are a negative, positive, or 0-valued integer.
So, let’s do constant propagation analysis! Remember that in constant propagation analysis, each value is either
In the textbook, we keep these things separate. The textbook defines a monotone structure to consist of a lattice
Because of this, we also introduce abstract data values
Now, statements are in the form:
where the
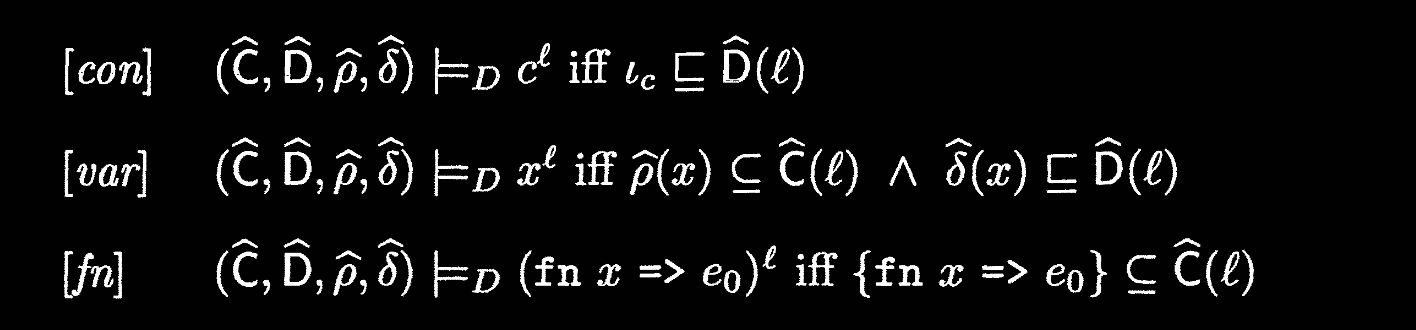
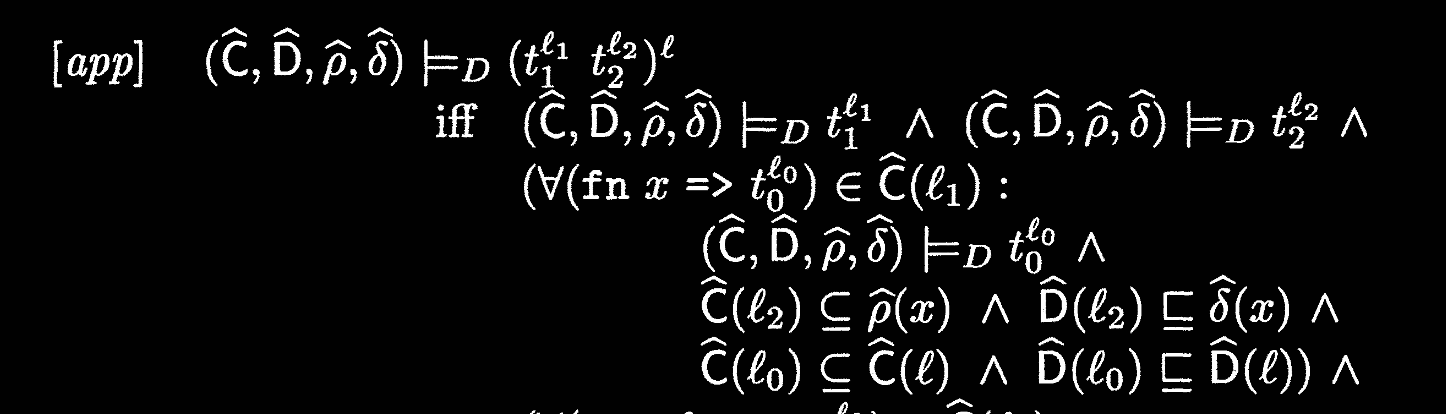
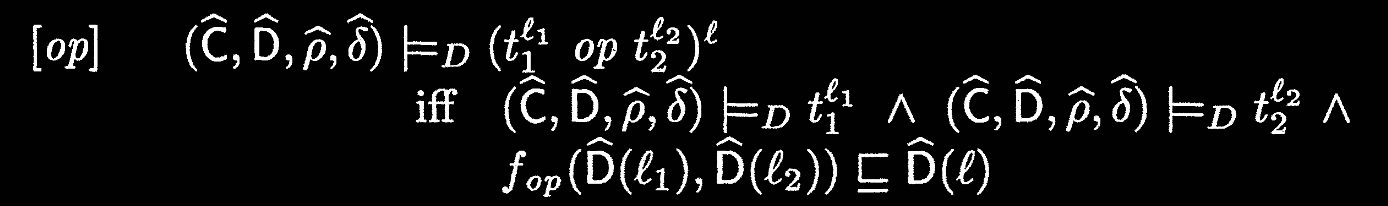
Explanations:
- For constants, the constant should be in our analysis.
- For application, we propagate following our rule-of-thumb as before: argument to parameter, lambda body to application.
- For binary operations, calling the appropriate lifted operation on the arguments should be less than the analysis for the whole expression
Alternatively, in the lecture notes, we define
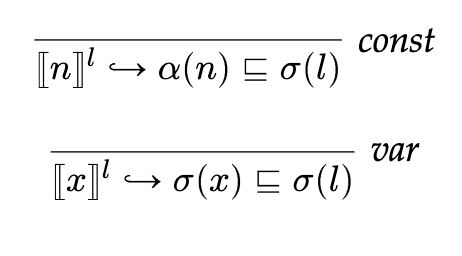

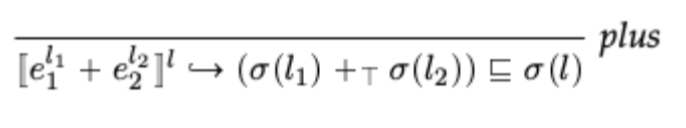
where
Context sensitivity: k-CFAs and m-CFAs
Note
This references §3.6 of the textbook.
So what do we mean by context sensitivity of analyses? Let’s look at the following expression:
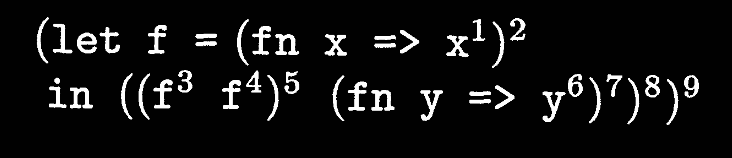
In our current analysis, we note the following:
xinfn x => xcan take on one of two values:fn x => xfrom (4) andfn y => yfrom (5).- We return
xin (5) and (8); sincexcan be either value, (5) and (8) must also be either value.
However, the expression ultimately evaluates to fn y => y, meaning our analysis is imprecise! It thinks the expression could have two possible values, but that’s wrong. The key error here is lack of context—the analysis can’t distinguish between f f and (f f) (fn y => y), i.e., f (fn y => y). Only the second call is actually responsible for dictating the possible function values (9) can take on!
if we explicitly divide f into two different functions, called in different places, our analysis then works:
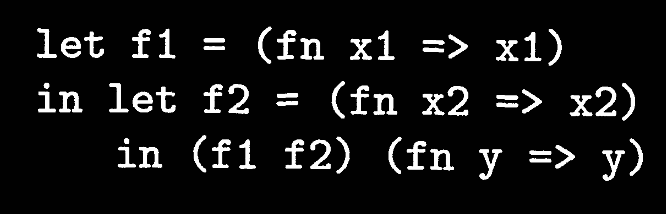
Here, the analysis proceeds as follows:
x1only takes onf2, andf2only takes onfn y => y.- By application,
(f1 f2)includes the fns in the body off1—i.e.,f2. - By application again,
f2includes only the fns in the body off2—i.e.,fn y => y
The analysis can now realize that x1 can only be bound to fn x2 => x2, and x2 can only be bound to fn y => y. Thus, when calling the overall expression, only fn y => y is a possible value.
The difference here is context. The variable f occurs in different places, but in each place, its argument x can take on different values, as was made clear when we split its uses out into two different functions f1 and f2. The difference is in the expressions that were evaluated before each call of f—basically, the call stack that led to this application of f! This is what we mean by the context and by “occurring in different places.”
In the literature, context-sensitivity is also referred to as polyvariance, with context-insensitivity referred to as monovariance.
k-CFAs
In a
Our abstract environment
Of course, we need to now store contexts in our analysis too. Indeed, at each subexpression point, we want to store the mapping from all free variables in a term to the (up to)
We call this mapping a context environment. The context environment
Our abstract value domain
Uniform
-CFA analysis vs. -CFA analysis Confusingly, a uniform
-CFA analysis differs from a -CFA analysis. In the uniform -CFA analysis, our treatment of the abstract cache mirrors the abstract environment, taking a product of labels and contexts: However, in a regular
-CFA, we have . I believe these are functionally equivalent, and just differ in terms of framing? We call the former “uniform” since both the abstract environment and abstract cache use the same precision.
So how do we go about performing this analysis? First, let’s look at the notation for our acceptability judgment now:
Our judgment is now with respect to a context environment
Now, let’s look at function introduction:
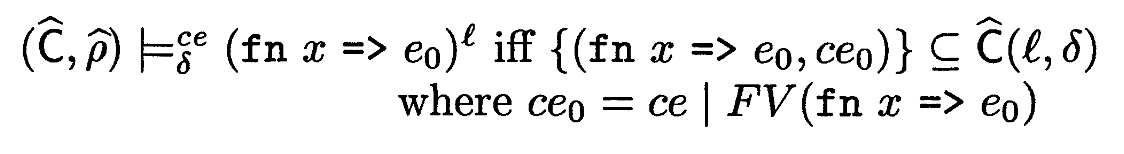
The analysis information we store at
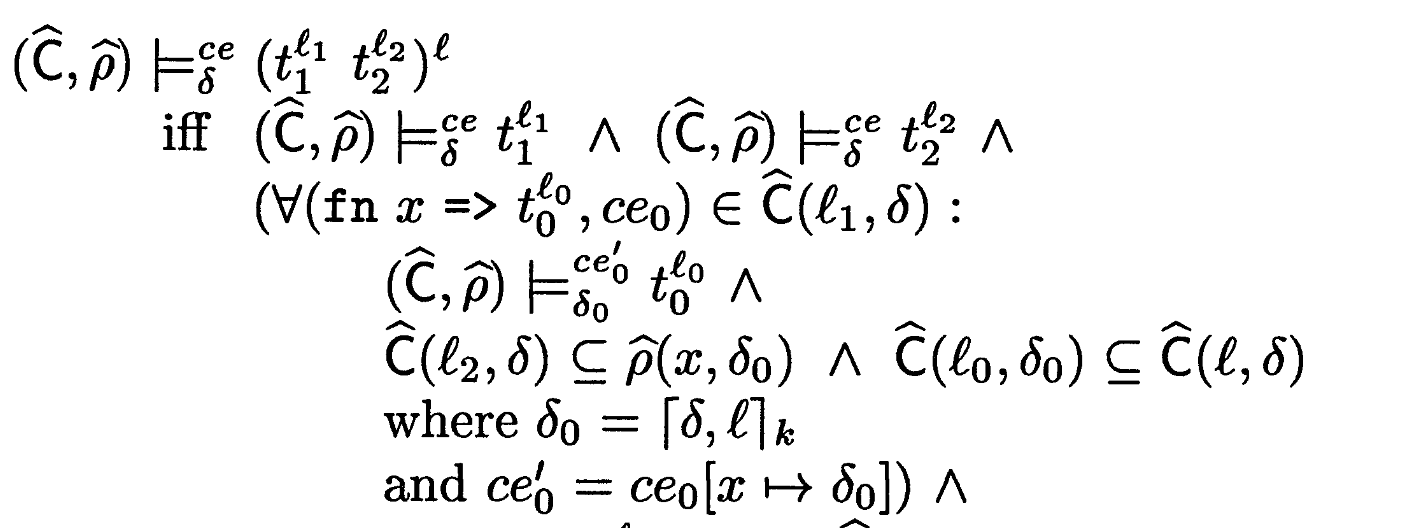
Let’s unpack this rule:
- Let’s say
and are the current environment and context as we’re performing this analysis. - Checking the body
involves a new context environment and a new context . now contains , the most recent application. is their notation for ” with appended, then truncated to the most recent .”
now maps from , the newly bound variable, to the context at this point. - Remember that
is the mapping for all free variables in the lambda. isn’t free in the lambda term; thus provides a mapping for . - Remember that the meaning of a variable being in an environment is “whatever the call stack was up to when this variable was bound”
- We preserve free variables because inside
, is now free, and we want to retain that information as-is for .
- Remember that
- Remember the rule-of-thumb for how constraints propagate: argument flows to parameter, value of body flows to application:
- Argument flows to parameter:
- Body flows to application:
- Be careful about threading the right arguments in the right places!
- Argument flows to parameter:
And for completeness, here are the other two rules:
A worked example
TODO
Haven’t done this yet.
Tradeoffs & space complexity
Note
Also taken from the Harvard lecture slides.
So if adding context makes our analysis better, why not do it all the time?
The summary is that
Since
is a powerset of pairs , and there are pairs it follows that has height . Since we have the exponential worst case complexity claimed above.
By contrast, 0-CFA analysis corresponds to letting
From k-CFA to m-CFA
Note
Now we reference the above slides and this paper.
From above, it turns out
The reason this is is because objects are subtly different than closures. Within a closure, each variable could be bound in a different context. This is why our
By contrast, in OO languages, objects can’t capture outside variables. Instead, whenever they create a “closure,” they have to call a constructor that explicitly copies the variables into the object, so they can be referenced at that point. Think of how Rust handles closures internally: it explicitly creates a struct that copies all of the variables at that point into its own state:
let x = 4;
let f = || {
x + 1
}();is equivalent to
struct F {
x: u32,
}
impl F {
fn call(&self) -> u32 {
self.x + 1
}
}
let x = 4;
let f = (F { x }).call();Because of this, all variables are bound in the same context.
This is the core idea of
Cartesian Product Algorithm
See also
Read Cartesian Product Algorithm first!
For a language with multi-argument function calls, we can rephrase 0-CFA analysis to act on cartesian products of the arguments.
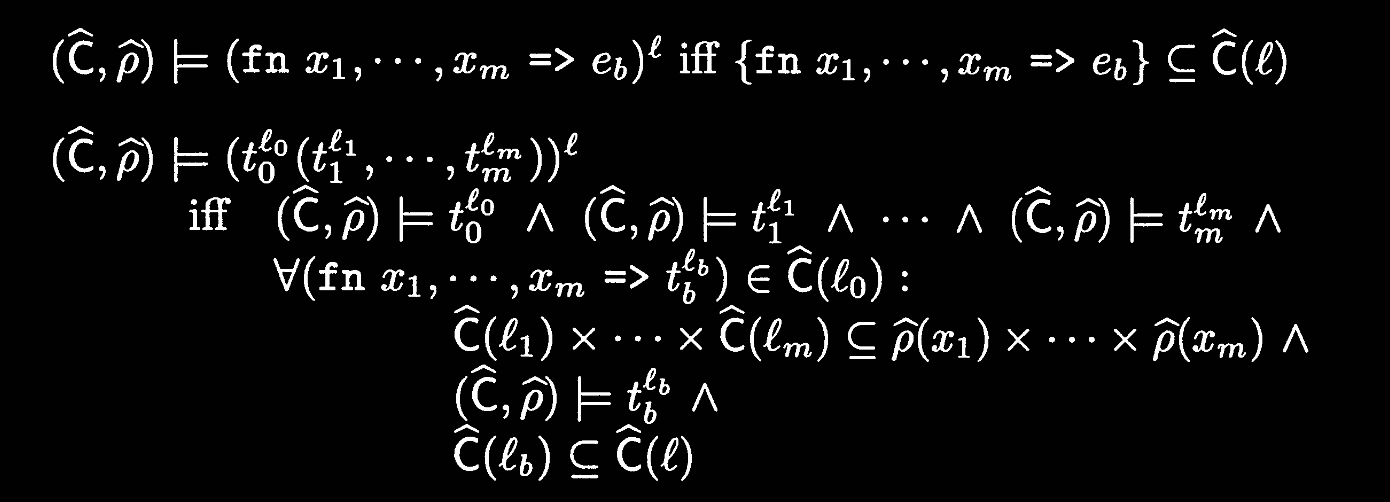
With the Cartesian Product Algorithm, we see a way of implementing context sensitivity in the presence of multi-variable functions. This is kind of implementing
In essence, following our rule of thumb, analysis flows from products of analyses on concrete values to products of analyses on abstract variables.
Practical implementation
Note
This references §3.3-3.4 of the textbook.
Okay. That was a lot of theory. In this section, we’re gonna cover how might we implement CFA constraint generation and solving in practice.
The goal is to find the smallest solution
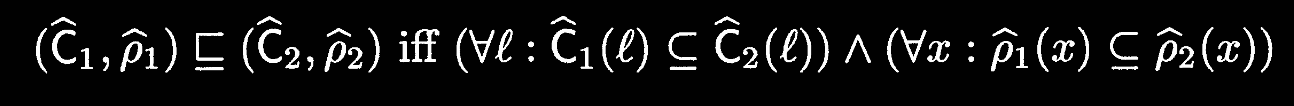
Our approach will be to reformulate the specification of
- We’ll change the spec in a syntax-directed manner
- We use this new spec to define an algorithm for generating constraints
- We’ll compute the least solution of this set of constraints.
Syntax-directed specification
Our syntax-directed reformulation ensures that every function body is analyzed at most once. We do this by moving body analysis into lambda introduction—instead of where it was in application, i.e., lambda elimination. This has the cost of analyzing potentially unreachable program fragments (e.g., analyzing the body of a function that’s never called).
Syntax-directed constraint generation
With this new spec, we can define a syntax-directed constraint generation algorithm!
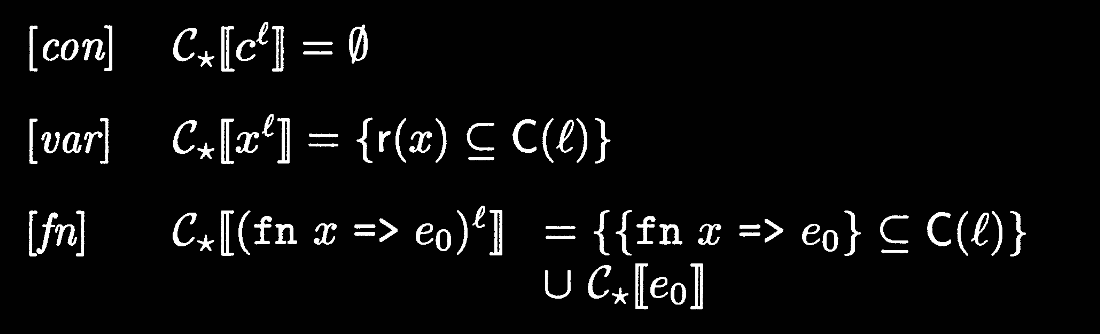
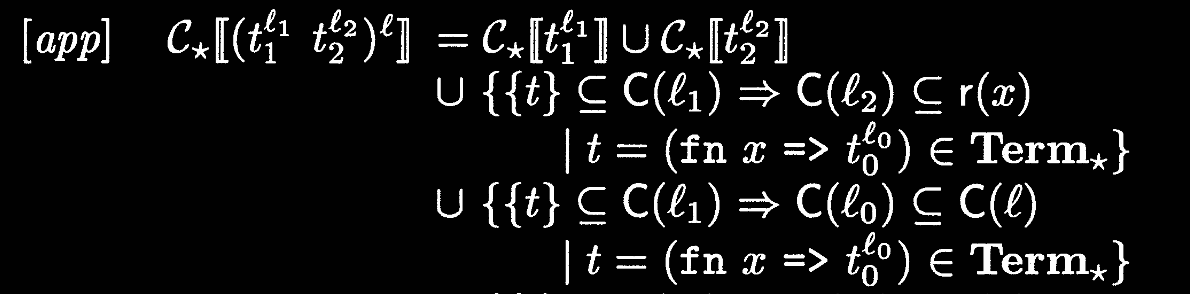
Notation notes
- We read
as . - What does it mean to have an implication be a subset of another set? The next section will clarify this!
Solving these constraints
How do we solve these constraints? There are two broad solutions:
- Fixed-point, complexity
over size of the expression . - On each iteration, we update the abstract cache as follows:
- For every label
in the environment - Get every constraint of the form
. will have one of two forms. We must transform into a set of terms: - If
is a set , return . - If
is , this means . - If
is of the form : - If
, transform . - Otherwise, return
. - When we say “transform,” we mean “do the same pattern matching we just did on
.”
- If
- Remember that we have to do this because we have that “implication subset” notation going on above.
- If
- Combine all transformed
items to yield .
- For every label
- Do the same with the abstract environment.
- On each iteration, we update the abstract cache as follows:
- Graph reachability****, complexity
. ^203nd2 - The nodes are all the variables and labels. Each node
contains the analysis, initially initialized to every term mentioned in a constraint. - A constraint
creates an edge - This edge is traversed only whenever
has a new term.
- This edge is traversed only whenever
- A constraint
creates edges , . - These edges are only traversed if
is in the analysis for .
- These edges are only traversed if
- The nodes are all the variables and labels. Each node
Either of these algorithms produce the least solution to
We can’t really check if an abstract environment and cache are acceptable for an expression though. This is important when we’re trying to optimize